09 技术奇点——人工智能的自我挑战(第3/4页)
具体来说,他们建立了三种机器人群体,第一种是被模仿对象,按照事先指定的规则进行复杂运动;第二种是模仿者,混入到第一组机器人中,尽力学习和模仿第一组的行为,尽力欺骗鉴定者;第三种是鉴定者,它的任务就是区分那些运动中的群体里谁是模仿者,谁是被模仿者。随着鉴定者能力的提高,模仿者的模仿行为也会越来越逼近被模仿者。于是,我们便可以利用训练好的模仿者搭建一个逼真的多主体模型,来对被模仿者群体进行模拟。这种模型就可以用于研究集体运动,比如可以根据摄像头记录的节假日热门景点的人群运动来训练出一个模型,强化对人群运动趋势的预测,对可能发生的拥堵踩踏事故发出预警。
机器的进化迭代过程比大自然快亿万倍。在这种对抗生成中,机器习得的逻辑已经远远超出人类的理解,可能成为一种“黑箱”。是追求“黑箱”,还是追求“白箱”,如何避免“黑箱”带来的不可知危险,这是对人类的一个挑战。
对偶网络
对偶网络仿佛对抗网络的一种镜像。
目前多数神经网络的训练依赖有标签的数据,即监督学习。而给数据标注标签是一项繁重的工作。据报道,谷歌的开源图片数据库Google Open Image Datasets中含有900万张图片,YouTube-8M中包含了800万段被标记的视频,而ImageNet作为最早的图片数据集,目前已有超过1400万张被分类的图片。这些精心标记的数据,大部分是由亚马逊劳务外包平台Amazon Mechanical Turk上5万名员工花费两年时间完成的。[7]
如何让机器在缺少标注数据的条件下工作,是未来人工智能的发展方向。2016年,微软亚洲研究院的秦涛博士等人在向NIPS(神经信息处理系统大会)2016提交的论文中提出了一种新的机器学习范式——对偶学习。大致思想是:
很多人工智能的应用涉及两个互为对偶的任务,例如从中文到英文的翻译和从英文到中文的翻译就互为对偶、语音处理中语音识别和语音合成互为对偶、图像理解中基于图像生成文本和基于文本生成图像互为对偶、问答系统中回答问题和生成问题互为对偶、在搜索引擎中给检索词查找相关的网页和给网页生成关键词互为对偶。这些互为对偶的人工智能任务可以形成一个闭环,使在从没有标注的数据中进行学习成为可能。对偶学习最关键的一点在于,给定一个原始任务模型,其对偶任务的模型可以给其提供反馈;同样的,给定一个对偶任务的模型,其原始任务的模型也可以给该对偶任务的模型提供反馈。从而这两个互为对偶的任务可以相互提供反馈,相互学习、相互提高。[8]
对偶网络利用这样一种精妙策略大大减少了对标注数据的依赖,我们从中可以再次洞见某种进化的哲学:进化是一种自我应答和自我循环的过程,从A到B,从B到A,互为镜像,但镜子并不清晰,各自掌握一半的秘密,没有仲裁,却可以在彼此猜测、参照中摇摇晃晃地前行。
深度学习的新边疆
以上两种神经网络方法只是不断涌现的新方法的典型代表。在深度神经网络方法之外,科学家也在积极探索其他路径。南京大学著名的机器学习专家周志华教授在2017年2月28日发布的一篇论文中,就与联合作者冯霁一起提出了一种创造性的算法,可以形象地称为“深度森林”(gcForest)算法。顾名思义,相对于深度学习强调神经网络的层数,这种算法重新利用了传统的“决策树”算法,但是强调“树”的层次。多层决策树的联合就形成了“森林”,通过精巧的算法设置,在数据规模和计算资源都比较小的情况下,在图像、声音、情感识别等应用上,都取得了不输于深度神经网络的成绩。这种新方法对参数设置不敏感,而且因为基于逻辑清晰的“树”方法,可能比深度神经网络更容易进行理论分析,从而避免人类难以理解机器具体运作逻辑上的“黑箱”问题。
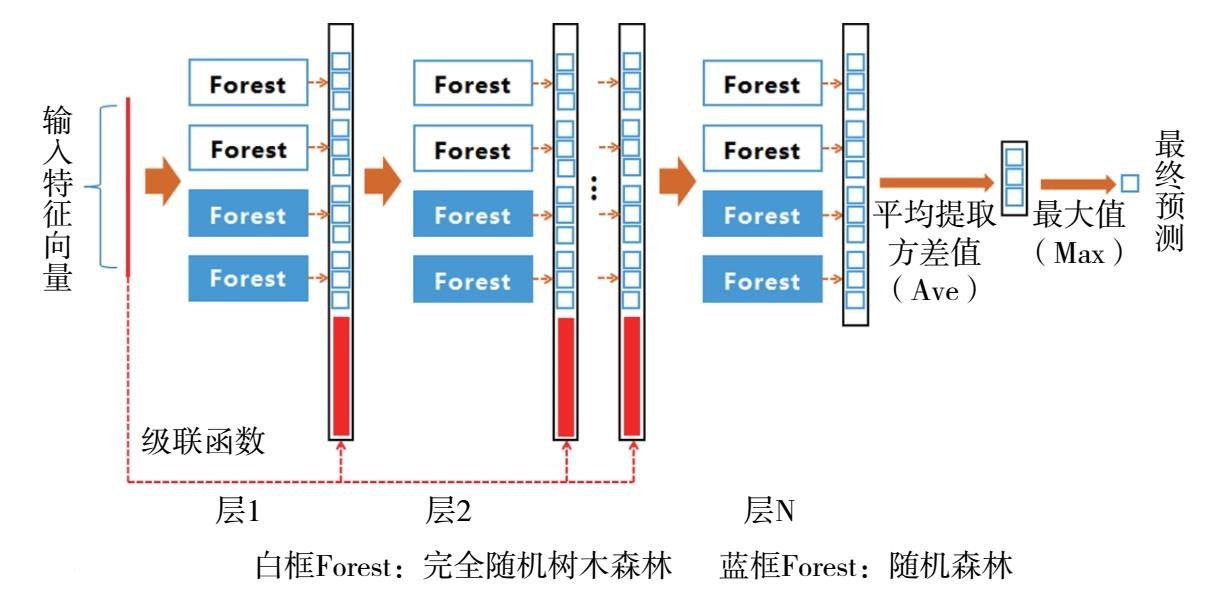
图9-6 多粒度级联森林结构
资料来源:https://arxiv.org/pdf/1702.08835.pdf
表9-1 在人脸识别上的精确比较
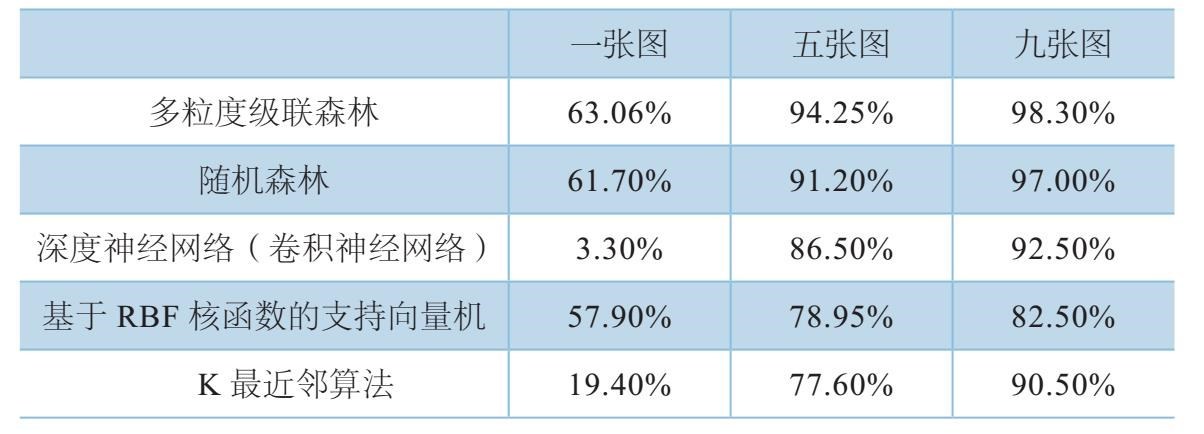
表9-2 在GTZAN数据库中的测试精确度比较
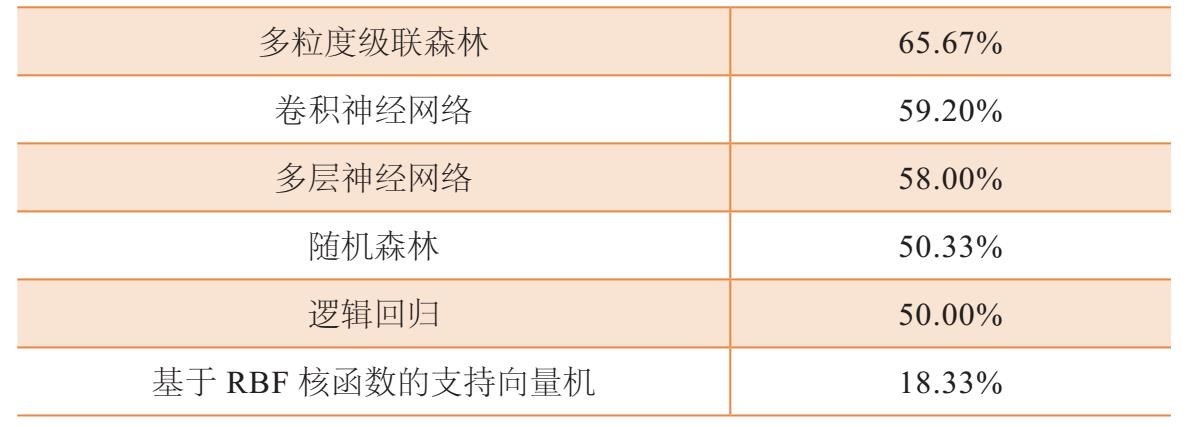
资料来源:https://arxiv.org/pdf/1702.08835.pdf
据智库“新智元”向周志华教授了解,“深度森林”的方法论意义在于探索深度神经网络以外的算法可能。深度神经网络的有效运作,需要巨大的数据和计算能力,深度森林有可能提供新的选择。当然,深度森林依然向深度神经网络借鉴了关键思想,比如对特征的提取和构建模型的能力。所以,它依然是深度学习的一个新颖分支。