09 技术奇点——人工智能的自我挑战(第2/4页)
在搜索结果页面下方,百度还提供了相关词搜索,比如美国新总统大笔一挥,签字退出前任费尽心机达成的TPP。这条新闻的相关搜索如图9-1所示。

图9-1 TPP相关词搜索结果
此外,搜索引擎还根据网友搜索热度排列出与TPP相关的热搜新闻,方便用户获取信息。

图9-2 与TPP相关的热搜新闻
这些都是通过对大量用户搜索的统计做到的,从而大大优化搜索体验,提升搜索速度,缓解数据处理压力。
可以说,数据引发的问题千奇百怪。数据并非均质的比特,而是和各种特殊人类活动场景相关,使得数据处理面临各种挑战。但从根本上来看,还是珍妮机与飞梭的矛盾——硬件的所有进步都会立刻被计算量和数据量吃掉。虽然硬件能力发展速度也很快,以相同成本下每18~24个月翻一番的速率增长(也称为摩尔定律)
Ian Goodfellow,Jonathon Shlens(乔纳森·舍琳)和Christian Szegedy在论文《Explaining and Harnessing Adversarial Examples》中给出了一个典型:
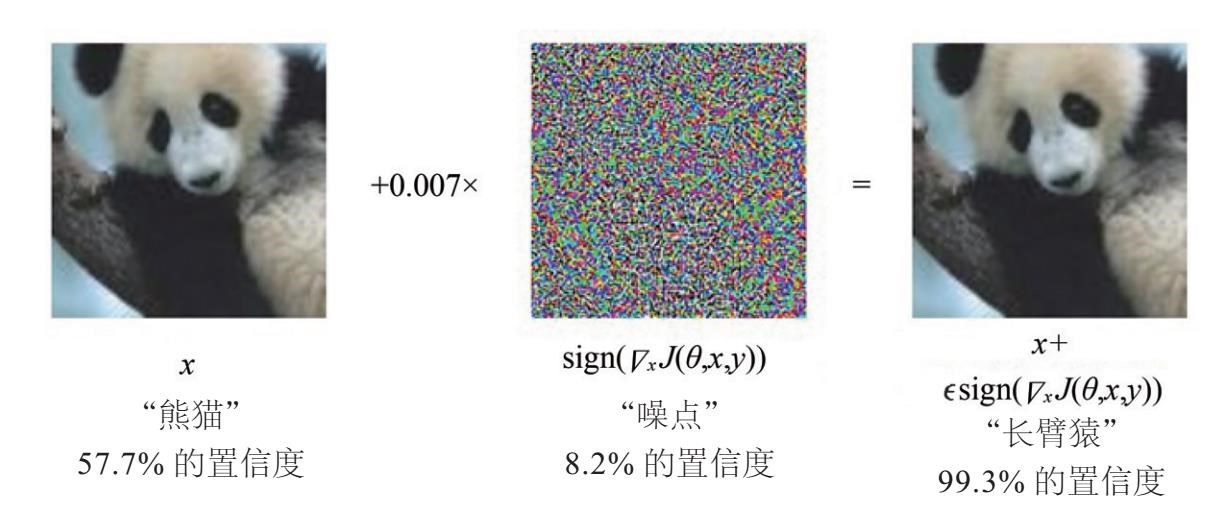
图9-5 深度学习对抗样本
资料来源:https://arxiv.org/pdf/1412.6572v3.pdf
在第一张图中,原始图像是熊猫,神经网络以57.7%的置信度判断为“熊猫”。
然后人类给图片加入微小的干扰,也就是第二张图所示的噪点。使用32位浮点值来执行修改,不会影响图像的8位表示。
最终得到第三张图。人眼完全看不出差别,但此时神经网络却诡异地以99.3%的置信度判断此图为长臂猿。
因为对抗性样本导致识别错误,有人将其当作深度学习的深度缺陷(Deep Learning’s Deep Flaws)。可是加州大学圣地亚哥分校的Zachary Chase Lipton(扎卡里·柴斯·立顿)在KDNuggets(美国一个大数据媒体)上发表文章,标题针锋相对,叫作(Deep Learning’s Deep Flaws)’s Deep Flaws,即《〈深度学习的深度缺陷〉一文的深度缺陷》[5]。该文认为深度学习对于对抗性样本的脆弱性并不是深度学习所独有的,在很多机器学习模型中普遍存在,进一步研究抵抗对抗性样本的算法将有利于整个机器学习领域的进步。
科学家抓住了“进化”的脆弱性本质,将错就错,把对抗看作一种训练办法,变阻碍为动力,艰难提升。大自然的进化本身就是高度脆弱的,无数生物“程序”被大自然淘汰,因为它们“出错”了。错误,就是进化的终极工具。而智慧就是在这个方生方死的过程中艰难升起。
对抗生成网络即人类对神经网络进行了特别设计,让其主动产生干扰数据来训练网络的能力。简单地说,对抗生成网络由两部分组成,一个是生成器(generator),另一个是鉴定器(discriminator)。生成器好比是一个卖假货的奸商,但是制造的山寨品高度仿真,而鉴定器好比高超的买家,需要鉴别货品真假。奸商的职责是想方设法欺骗买家(生成对抗性样本),后者则通过这种历练不断吸取教训,减少受骗概率。双方都在不断努力以达到目的,同时在彼此的“监督”下提升。看上去仿佛军事演习中的蓝军与红军展开激烈对抗,由此强化双方战斗能力,但没有硝烟。
这又是一个“共同进化”的例子,是进化的深刻哲学,不是战争,而是纠缠,是“在持久的摇摇欲坠中保持平衡”。
就对抗生成网络来说,我们要的是这个成熟的买家,还是那个高超的奸商呢?答案是都需要。二者是共同进化的必然要素。
奸商模型有什么用处?在很多情况下,我们会面临缺乏数据的情况,但可以通过生成模型来补足。制造样本,产生类似监督学习的效果,但实际上是非监督学习。
来自英国谢菲尔德大学的Wei Li(李伟)、Roderich Groß(罗德里赫·格鲁)和美国哈佛大学的Melvin Gauci(梅尔文·高斯)一起,基于对抗生成网络,开发了一种新的图灵学习方法,用于研究群体行为。[6]比如一群鱼中混进一些模仿鱼运动的假鱼,如何判断模仿行为的逼真度呢?使用传统的特征归纳法来区分是很难的,同一群鱼每次表现出的运动特征也不一定相似。这个团队决定让机器通过互相模仿自动建立群体模型,让机器自主推断自然物与模仿物的行为。该深度学习同时优化两种群体计算机程序,一个代表模型的行为,另一个代表分类器。该模型可以模仿监督学习下的行为,也可以辨别系统和其他模型之间的行为。