03 在大数据与深度学习中蝶化的人工智能(第9/11页)
我们审视一下这个过程,是否和我们描述过的深度学习概念模式十分相像?输入和输出在这里都有了,甚至每一次搜索行为都可以看作是对搜索引擎的一次训练。那么谁来告诉搜索引擎输出结果的好坏呢?是用户。用户的点击就是一种回答,如果用户没有点击排在前面的结果,而是去点击第二页的结果,这就是对系统的推荐做出了降权举动。
在这个过程中,搜索引擎不仅提高了推荐的准确性,还越来越懂得判断所收录网页的“好”与“坏”,渐渐学会了像人类一样去分辨网页。最初,它只会读取标题、关键字、描述等页面元素;而现在,百度这样的搜索引擎已经可以辨识出哪些是隐藏的虚假信息,哪些是广告,哪些是真正有价值的内容。
人通过搜索引擎获取信息的行为就是人与机器对话的过程。与以往的人机交互不一样,这个过程基于“自然语言”。相比图像识别、语音识别等,自然语言处理(Natural Language Processing,NLP)是搜索引擎最核心的基础技术。
王海峰认为思考和获得知识的能力成就了今天的人类,这种能力需要通过语言来找到思考的对象和方法,并外化为我们看、听、说和行动的能力。相对于这些能力,语言是人类区别于其他生物的最重要的特征之一。视觉、听觉和行为能力不仅为人类所拥有,动物也有,甚至很多动物的视觉、听觉,包括行动能力比人类还强,但是语言是人类特有的。而建立在语言之上的知识总结、提炼、传承以及思考,也都是人类特有的。
从人类历史之初,知识就以语言的形式进行记录和传承,用来书写语言的工具不断改进:从甲骨到纸张,再到今天的互联网。所以不管是百度还是谷歌,都认为自然语言处理对整个人工智能的未来都是非常大的挑战。相比之下,语音识别,如声音到文字,或是文字到声音,实际上解决的是一个信号转换问题,但语言不是,语言和人的知识、思维整体相关。
像AlphaGo这样的项目,对于普通人来讲是一件非常震撼的事情,我们也认为它是一个很大的成绩。但是我们不能忽略它的特点:基于完全信息、规则是明确的、空间是封闭的和特定的。为围棋训练出来的智能系统下象棋就不好用。相比较而言,自然语言的处理是更难解决的一个问题。对于下围棋来说,只要计算能力和数据充分,就几乎没有不确定性,而语言问题存在太多不确定性,如语义的多样性。
为了让计算机能够“理解”和生成人类语言,科学家做了大量的工作。在百度,基于大数据、机器学习和语言学方面的积累,研发出了知识图谱,构建了问答、机器翻译和对话系统,建立了可以分析、理解问题(query)及情感的能力。
仅就知识图谱来说,基于不同的应用需求可分为三类:实体图谱(entitygraph)、关注点图谱(attentiongraph)和意图图谱(intentgraph)。
在实体图谱里,每一个节点都是一个实体,每个实体都有若干个属性,节点之间的连接是实体之间的关系。目前百度的实体图谱已经包含了数亿实体、数百亿属性和千亿关系,这些都是从大量结构化和非结构化数据中挖掘出来的。
现在我们来看一个例子,假如有人搜索:窦靖童的爸爸的前妻的前夫。
这句话里包含的人物关系是非常复杂的,然而,我们的推理系统可以轻松地分析出各实体之间的关系,并最终得出正确答案。
百度的自然语言处理技术还可以分析复杂的语法,甚至辨识句子的歧义,而不仅仅是字面匹配。
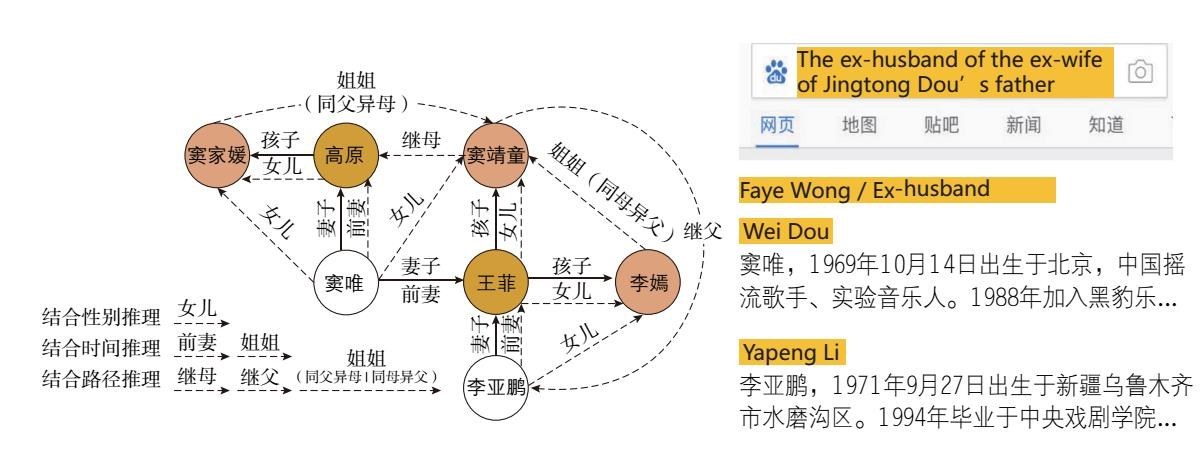
图3-5 人物关系图1
再来看另外一个例子:梁思成的儿子是谁;梁思成是谁的儿子。
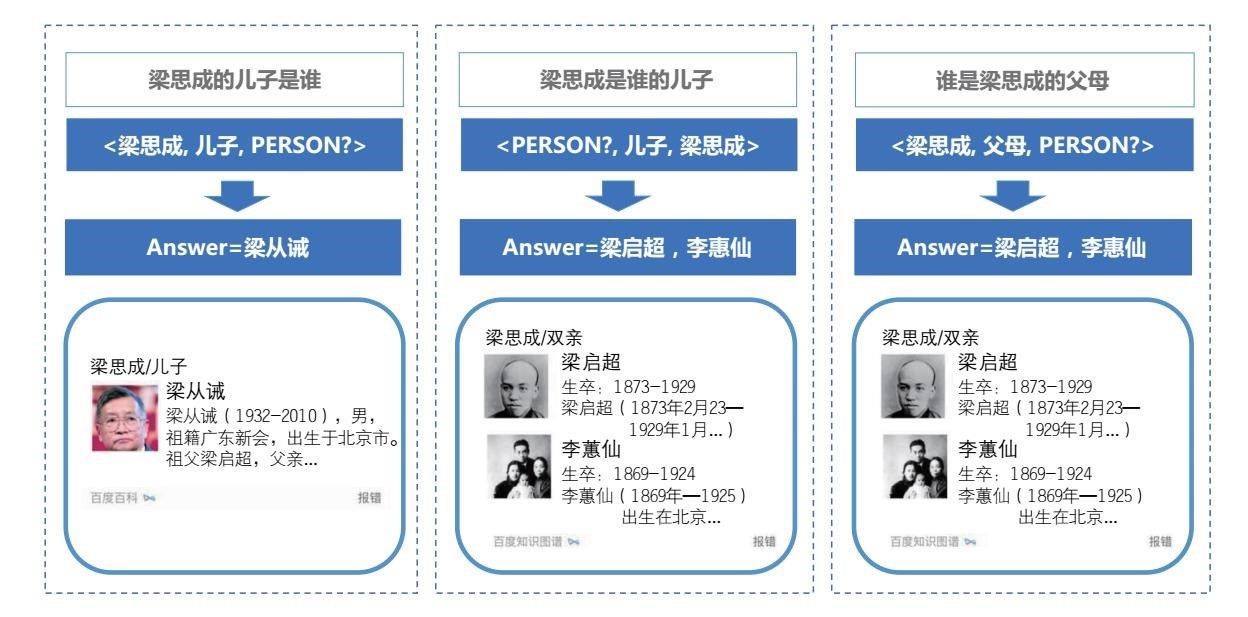
图3-6 人物关系图2
如果使用传统的基于关键词的搜索技术,我们将会得到几乎相同的结果。然而,经过语义理解技术的分析,机器可以发现这两个句子的语义是完全不一样的,相应地就能从知识图谱中检索到完全不同的答案。
还有第三句话:谁是梁思成的父母。从字面上来看,这跟第二个句子不同,但是经过语义理解技术,机器发现这两个句子要找的是同一个对象。
深度学习技术进一步增强了自然语言处理能力。百度从2013年开始在搜索引擎中应用DNN模型,至今已经对这个模型进行了几十次的升级迭代,DNN语义特征是百度搜索里非常重要的一个特征。其实,不仅搜索结果相关度变得更高,在篇章理解、关注点感知和机器翻译等方面也都有大幅提升。